這幾天在準備下個月客家語文學會線上講座的簡報, 為此複習了之前所寫的 GitHub 筆記, 發現其實 README.md 中使用的 Mark down 語法也可以用來寫網頁, 語法超簡單. 本篇是在下面這篇筆記基礎上, 再參考網路上的資料重新整理而成 :
以下針對十個常用網頁元素改用較簡單的 Markdown 語法來撰寫, GitHub 會將 .md 的文件翻譯成真正的 HTML 碼 :
1. 標題 (轉成 h1~h6) :
標題的 mark down 符號為 #, h1~h6 分別使用 1~6 個 # 號, 後面跟著標題文字, 例如 :
# h1 標題
## h2 標題
### h3 標題
#### h4 標題
##### h5 標題
###### h6 標題
結果如下 :

轉成的 HTML 如下 :
<h1 id="h1-標題">h1 標題</h1>
<h2 id="h2-標題">h2 標題</h2>
<h3 id="h3-標題">h3 標題</h3>
<h4 id="h4-標題">h4 標題</h4>
<h5 id="h5-標題">h5 標題</h5>
<h6 id="h6-標題">h6 標題</h6>
可見它會將文字內容拿來當 id.
2. 段落 (轉成 p) :
段落的 mark down 為兩個以上空格加上跳行, 例如 :
下面有三個段落:
段落 1
段落 2
段落 3
注意, '下面有三個段落:' 後面是直接跳行, 而 '段落 1' ~ '段落 3' 後面則是有兩個空格再跳行, 結果如下 :

<p>下面有三個段落:
段落 1<br />
段落 2<br />
段落 3</p>
可見它是把整個當一個段落, 中間用 <br> 跳行.
3. 水平分隔線 (轉成 hr) :
水平分隔線的 mark down 可用三個以上的 * (星號), - (負號), 或 _ (底線) 表示, 中間可以有一個以上的空格, 但該列不能為有其他字元, 例如 :
***
* * *
---
- - -
___
_ _ _
結果如下 :

感覺線條有點粗, 轉成的 HTML 如下 :
<hr />
<hr />
<hr />
<hr />
<hr />
<hr />
4. 文字效果 :
文字效果主要有粗體, 斜體, 底線, 刪除線, 上標, 下標等.
(1). 斜體 :
斜體是在文字左右用一個 * (星號) 或 _ (底線) 包起來, 例如 :
*斜體文字*
_斜體文字_
(2). 粗體 :
粗體是在文字左右用兩個 * (星號) 或 _ (底線) 包起來, 例如 :
**粗體文字**
__粗體文字__
(3). 粗斜體 :
粗體是在文字左右用三個 * (星號) 或 _ (底線) 包起來, 例如 :
***粗斜體文字***
___粗斜體文字___
(4). 文字加底線 :
文字加底線是直接用 HTML 的 <u> 與 </u> 包起來, 例如 :
<u>文字加底線</u>
(5). 刪除線 :
刪除線是在文字左右用兩個 ~ (波浪) 包起來, 例如 :
~~文字加刪除線~~
(6). 上標與下標 :
上標是直接用 HTML 的 <sup> 與 </sup> 包起來; 下標則是用 <sub> 與 </sub> 包起來, 例如 :
x<sub>a</sub><sup>2</sup>
(7). 注音 :
上標是直接用 HTML 的 <sup> 與 </sup> 包起來, 例如 :
<ruby>鱻<rt>ㄒㄧㄢ</rt></ruby>
結果如下 :

轉成的 HTML 如下 :
<p><em>斜體文字</em>
<em>斜體文字</em></p>
<p><strong>粗體文字</strong>
<strong>粗體文字</strong></p>
<p><strong><em>粗斜體文字</em></strong>
<strong><em>粗斜體文字</em></strong></p>
<p><u>文字加底線</u></p>
<p><del>文字加刪除線</del></p>
<p>x<sub>a</sub><sup>2</sup></p>
<p><ruby>鱻<rt>ㄒㄧㄢ</rt></ruby></p>
5. 清單 :
清單有符號清單與編號清單兩種, 前者是無序的, 會轉成 ul 與 li 元素; 後者則以數字為序, 會轉成 ol 與 li 元素.
(1). 符號清單 :
符號清單的 mark down 可用一個 * (星號), + (加號) 或 - (負號) 開頭, 後面跟著一個空格, 然後是清單項目的文字, 例如 :
* 德魯納酒店
* 非常律師禹英禑
+ 馬氏文通
+ 事林廣記</li>
- 春上村樹
- 大江健三郎
結果如下 :

可見 Mark down 一律轉出 bullet 效果的清單, 轉成的 HTML 如下 :
<ul>
<li>德魯納酒店</li>
<li>非常律師禹英禑</li>
<li>馬氏文通</li>
<li>事林廣記</li>
<li>春上村樹</li>
<li>大江健三郎</li>
</ul>
(2). 編號清單 :
編號清單的 Mark down 語法是編號後面加一個小數點, 空一格 (此為必要) 再接清單項目文字, 美跳一列就會自動增量顯示下一個項目編號, 但只能用數字, 用英文字母 A. B. C. 無效, 例如 :
1. 德魯納酒店
2. 非常律師禹英禑
3. 馬氏文通
4. 事林廣記
5. 春上村樹
6. 大江健三郎
結果如下 :

轉成的 HTML 如下 :
<ol>
<li>德魯納酒店</li>
<li>非常律師禹英禑</li>
<li>馬氏文通</li>
<li>事林廣記</li>
<li>春上村樹</li>
<li>大江健三郎</li>
</ol>
(3). 巢狀清單 :
巢狀清單是指套疊兩層以上的清單, 首先來看內外層都是編號清單的組合 :
* 韓劇
- 德魯納酒店
- 非常律師禹英禑
* 古籍
+ 馬氏文通
+ 事林廣記
* 日本作家
- 春上村樹
- 大江健三郎
結果如下 :

可見第一層會用實心圓點 (solid bullet), 而第二層改用空心圓點. 轉成的 HTML 如下 :
<ul>
<li>韓劇
<ul>
<li>德魯納酒店</li>
<li>非常律師禹英禑</li>
</ul>
</li>
<li>古籍
<ul>
<li>馬氏文通</li>
<li>事林廣記</li>
</ul>
</li>
<li>日本作家
<ul>
<li>春上村樹</li>
<li>大江健三郎</li>
</ul>
</li>
</ul>
其次測試外層是符號, 內層是編號的組合 :
* 韓劇
1. 德魯納酒店
2. 非常律師禹英禑
* 古籍
1. 馬氏文通
2. 事林廣記
* 日本作家
1. 春上村樹
2. 大江健三郎
結果如下 :

可見內層的編號清單會使用小寫羅馬數字, 轉成的 HTML 如下 :
<ul>
<li>韓劇
<ol>
<li>德魯納酒店</li>
<li>非常律師禹英禑</li>
</ol>
</li>
<li>古籍
<ol>
<li>馬氏文通</li>
<li>事林廣記</li>
</ol>
</li>
<li>日本作家
<ol>
<li>春上村樹</li>
<li>大江健三郎</li>
</ol>
</li>
</ul>
最後來測試外層是編號, 內層是符號的組合 :
1. 韓劇
- 德魯納酒店
- 非常律師禹英禑
2. 古籍
+ 馬氏文通
+ 事林廣記
3. 日本作家
* 春上村樹
* 大江健三郎
結果如下 :

可見外層會用阿拉伯數字, 內層會用空心圓點, 轉成的 HTML 如下 :
<ol>
<li>韓劇
<ul>
<li>德魯納酒店</li>
<li>非常律師禹英禑</li>
</ul>
</li>
<li>古籍
<ul>
<li>馬氏文通</li>
<li>事林廣記</li>
</ul>
</li>
<li>日本作家
<ul>
<li>春上村樹</li>
<li>大江健三郎</li>
</ul>
</li>
</ol>
而內外層都是編號的組合無法使用, 因為會導致編號錯亂.
參考 :
6. 表格 :
表格的 mark down 使用 | 來區隔欄位, 用內容為 ---- 的一列來區隔表頭與其他列, 若要設定各欄對齊方式, 可在區隔列以下列為內容 :
- :---- (靠左對齊)
- :-----: (置中對齊)
- ----: (靠右對齊)
例如 :
|第一欄 |第二欄 |
|----|----|
|第一列第一欄 |第一列第二欄 |
|第二列第一欄 |第二列第二欄 |
結果如下 :
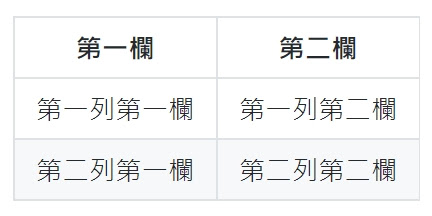
可見表頭預設是粗體置中對齊, 轉成的 HTML 如下 :
<table>
<thead>
<tr>
<th>第一欄</th>
<th>第二欄</th>
</tr>
</thead>
<tbody>
<tr>
<td>第一列第一欄</td>
<td>第一列第二欄</td>
</tr>
<tr>
<td>第二列第一欄</td>
<td>第二列第二欄</td>
</tr>
</tbody>
</table>
下面範例是設定左欄靠左對齊; 右欄靠右對齊 :
|第一欄 |第二欄 |
|:----|----:|
|第一列第一欄 |第一列第二欄 |
|第二列第一欄 |第二列第二欄 |
結果如下 :

轉成的 HTML 如下 :
<table>
<thead>
<tr>
<th style="text-align: left">第一欄</th>
<th style="text-align: right">第二欄</th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align: left">第一列第一欄</td>
<td style="text-align: right">第一列第二欄</td>
</tr>
<tr>
<td style="text-align: left">第二列第一欄</td>
<td style="text-align: right">第二列第二欄</td>
</tr>
</tbody>
</table>
7. 圖片 :
圖片的 mark down 語法為 :

其中替代文字即 img 標籤的 alt 屬性值, 圖檔位置可以用完整 URL, 也可以用相對路徑. 注意, 替代文字與圖檔位置都不可以用括號括起來, 例如 :

或使用完整 URL :

結果如下 :

轉成的 HTML 如下 :
<img src="https://yaohuang1966.github.io/images/cat.jpg" alt="alt 可愛的小咪" />
8. 超連結 :
超連結的 mark down 語法為 :
[連結名稱](連結網址){:屬性設定}
連結名稱就是 a 標籤的內容文字, 後面的 {} 可有可無, 這是用來設定屬性的, 若要在新頁籤開啟網頁可用 {:target="_blank"}, 例如 :
[Google](https://www.google.com.tw){:target="_blank"}
結果如下 :

轉成的 HTML 如下 :
<a href="https://www.google.com.tw" target="_blank">Google</a>
也可以設定網頁內超連結 (稱為 anchor), 點擊後會前往同一網頁內的特定錨點, 首先用下列語法在網頁中設定一個錨點 :
{#錨點名稱}
例如在長網頁底下通常會有按 "Top" 或 "返回上面" 超連結回到最上面的功能, 可設為 :
{#top}
然後在底下建立一個頁內超連結例如 :
[返回頂端](#top)
小括弧裡面這時不是放 URL, 而是錨點名稱, 結果如下 :

按此超連結就會回到 {#top} 所在的頁面頂端. 轉成的 HTML 如下 :
<a href="#top">返回頂端</a>
9. 音訊 :
Mark down 沒有音訊的語法, 而是直接嵌入 audio 標籤, 例如 :
<audio src="media/your_answer_clip.mp3" controls>不支援 audio</audio>
結果如下 :

10. 視訊 :
Mark down 沒有視訊的語法, 而是直接嵌入 video 標籤, 例如 :
<audio src="media/your_answer_clip.mp3" controls>不支援 audio</audio>
結果如下 :

完整範例如下 :
產生此範例網頁的 Mark down 原始碼如下 :
參考 :