本篇繼續整理 "深度學習的16堂課" 這本書的讀後筆記, 本系列之前的文章參考 :
以下是讀完第三章 "機器藝術-對抗式生成網路概述" 的摘要 :
- 對抗式生成網路 (GAN, Generative Adversarial Network) 是 2014 年由當時還是 Yoshua Bengio 實驗室博士生的 Ian Goodfellow 所構想出來的一種深度學習演算法 (他在史丹佛讀書時則是吳恩達的學生), 此演算法建構的生成模型 (generative model) 可以自動生成沒有出現過的東西, 例如模仿莎士比亞風格的名言, 旋律, 或抽象的藝術品. Ian Goodfellow 的創見來自他將兩個神經網路組合成一個深度學習模型的突發奇想, 然後訓練它們使其彼此互相競爭. 這兩個網路一個是用來用來產生假圖的生成器 (generator), 另一個則是用來鑑別真假的鑑定器 (discriminator), 循環競爭促使生成器產生更精良的假圖, 同時也使鑑定器進化出更好的鑑別能力, 最終讓模型生成風格與原始訓練圖片非常接近的假圖. 2014 年 Ian Goodfellow 在 NeurIPS 大會發表了 GAN, 並展示了用 GAN 生成的手寫數字, 人臉, 以及飛機, 汽車, 狗等圖片, 這些都是利用 MNIST 與 CIFAR-10 等資料集訓練出來的. Ian Goodfellow 目前於蘋果公司擔任機器學習總監.
- 2016 年美國工程師Alec Raford 在 GAN 的基礎上加入卷積神經網路, 提出 Deep convolution GAN (深度卷積對抗式生成網路), 利用所謂的潛在空間 (latent space) 生成更逼真的圖片. 潛在空間可以說是真圖的濃縮特徵, 可用來協助生成器生成圖片. 潛在空間的概念與詞向量空間類似, 它用高維向量來表示圖片中的不同特徵, 高維空間的每個軸代表不同的意義, 例如性別差異, 年齡大小或有無戴眼鏡等, 空間中的每個點代表一張圖片 (與詞向量空間中某點代表某詞類似), 兩個點位置越靠近表示兩點所代表的圖片越相似, 將這些點的座標向量進行運算, 其結果代表意義上的移動, 例如將 '戴眼鏡的男人' 減掉 '沒戴眼鏡的男人', 再加上 '沒戴眼鏡的女人' 運算後得到的向量會非常接近 '戴眼鏡的女人' 這個點.
- GAN 生成圖片的展示 :
http://bit.ly/InterpCeleb
下面這個網頁使用 GAN 產生假的人臉, 猜猜看哪個是真人臉孔 :
# https://www.whichfaceisreal.com/ - 2017 年柏克萊大學人工智慧實驗室 (BAIR) 提出的 CycleGAN 可以將照片轉換成不同的藝術風格, 稱為風格轉移 (style transfer) :
# https://junyanz.github.io/CycleGAN/
其應用範例例如 :
(1). 將莫內的畫轉成照片, 或者將照片轉成莫內畫風
(2). 將斑馬變成馬, 或者將馬變成斑馬
(3). 將春景變成冬景
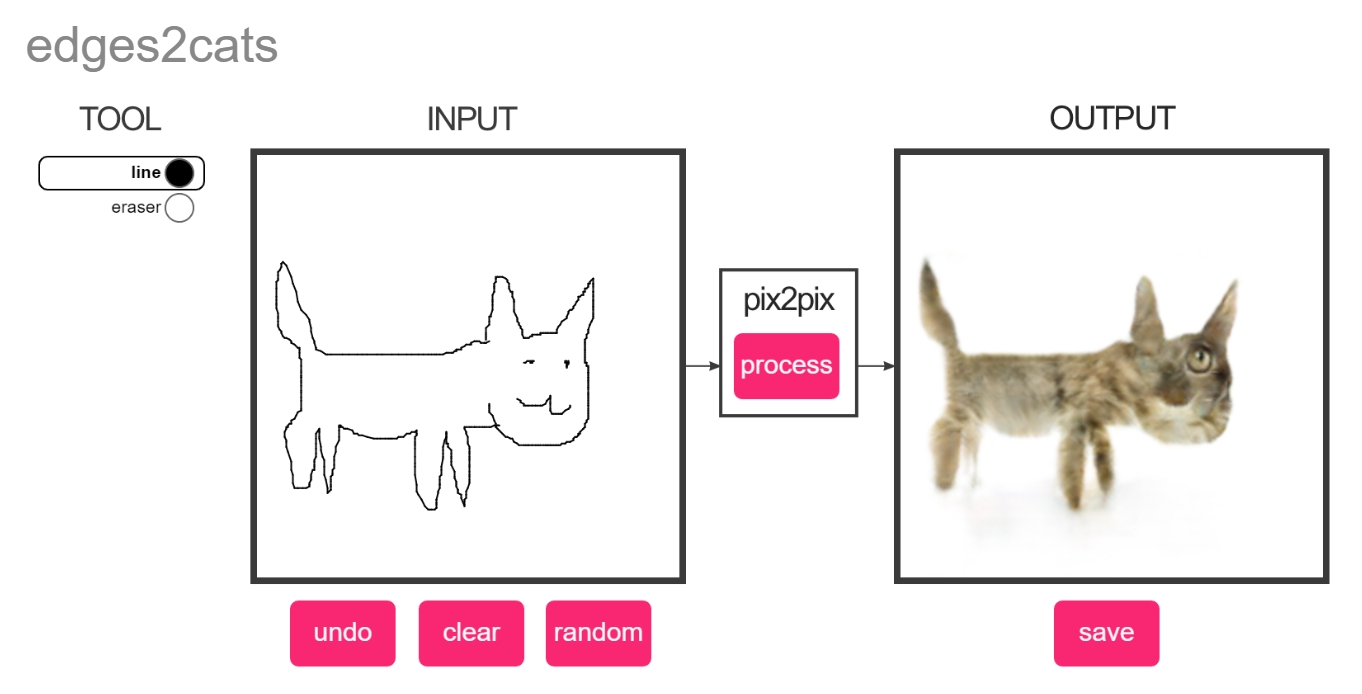
BAIR 實驗室還推出另一個稱為 conditional GAN (cGAN) 的應用 : pix2pix, 可將手繪圖案變成照片 :
# https://affinelayer.com/pixsrv/index.html
在左邊 INPUT 框內繪製主題圖案 (例如貓), 按中間的 process 鍵就會在右方框產生圖片, 因為它會依據輸入條件 (即所繪製的圖形) 來產生結果, 故稱為條件式 GAN (cGAN) :
- 另外一個 GAN 應用是 Han Zhang 等人提出的 StackGAN, 它是將兩個 GAN 網路堆疊起來, 第一個 GAN 先產生較粗糙低解析度的小圖 (建立基本輪廓與顏色), 結果再送至第二個 GAN 來轉成高解析度的大圖. 其獨特之處是它可以從文字敘述 (條件) 作為輸入來產生圖片, 參考 :
# 使用Keras實現StackGAN
# https://github.com/Vishal-V/StackGAN
# Let’s Read Science! “StackGAN: Text to Photo-Realistic Image Synthesis” - 深度學習在影像處理方面的應用也非常多, 例如傳統影像處理軟體只能對整個圖片進行降躁, 但透過深度學習就能在不同區域進行不同的降躁處理. 其它的應用例如將原本全黑圖片調亮, 或調整背景光源等, 參考 :
沒有留言 :
張貼留言