# Python + Spark 2.0 + Hadoop 機器學習與大數據分析實戰 (林大貴, 博碩)

作者有為此書設立網站, 臉書社團與粉絲團, 參考 :
# http://pythonsparkhadoop.blogspot.tw/
# https://facebook.com/hadoopspark
# https://facebook.com/groups/hadoopspark
全書範例程式可在博碩網站下載 :
# http://www.drmaster.com.tw/download/example/MP21622_example.zip
此書作者為從事大數據與機器分析工作, 具有多年實務經驗之業內人士, 故此書內容實作性強, 又兼顧基本觀念的介紹. 本書以 Python 為程式語言開發 Apache Spark 應用程式存取 Hadoop HDFS 上的分散式大數據, 此架構具有多重優點: Python 語言簡明易學具高度生產力; 基於記憶體 (in-memory) 運算的 Apache Spark 叢集運算框架可進行高效能之大數據運算; 而 Hadoop HDFS 則為大數據提供彈性, 可靠, 與易擴容之分散式檔案系統.
此書 1~9 章介紹建立 Python + Spark 2.0 + Hadoop 機器學習與大數據分析架構所需工具如 Hadoop Multinode Cluster, Python Spark 與 Scala 語言, Anaconda 等工具程式之安裝. 10~12 章為 Python Spark RDD, 整合開發環境與推薦引擎之介紹. 第 13 章以後即為機器學習部分, 直到最後的第 22 章. 以下是大略看過第一章後之摘要 :
- 機器學習的應用範例 : 推薦引擎, 定向廣告, 需求預測, 垃圾郵件過濾, 醫學診斷, 自然語言處理, 搜尋引擎, 詐騙偵測, 證券分析, 視覺辨識, 語音識別, 手寫識別等.
- 所謂機器學習是利用演算法以歷史資料進行訓練來產生模型 (監督式機器學習), 然後利用這模型對新資料進行預測. 訓練資料主要由 feature (資料特徵, 例如溫溼度, 氣壓, 風向等) 與 label (資料標籤, 即欲預測之項目, 例如氣候是陰, 晴, 或雨, 雪等) 組成. 機器學習可大略分成訓練與預測兩個階段.
- 監督式學習中的資料標籤依所欲預測的項目屬性, 所用的演算法可分為 :
(1) 二元分類 : 是非題, 例如只要預測下雨或不下雨.
(2) 多元分類 : 選擇題, 例如要預測是晴天, 陰天, 雨天, 或是下雪.
(3) 迴歸分析 : 計算題, 例如要預測今日的氣溫.
而非監督式學習因為沒有要預測的目標 (即無 label), 所以是用集群分析將資料分成幾個差異性較大之群組, 群組內相似度最高. - Apache Spark 原先是加州大學柏克萊分校 AMPLab 的 Matei Zaharia 於 2009 年所開發的一種開放原始碼叢集運算架構, 於 2010 年以 BSD 授權釋出原始碼成為開源專案, 2013 年 Spark 專案捐贈給 Apache 基金會.
- Spark 允許用戶將資料載入 Cluster 叢集記憶體內進行多次反覆運算, 是一個具有彈性, 用途廣泛之大數據運算平台, 非常適合實作機器學習演算法. 其特色有四 :
(1) 運算速度快
Spark 是基於記憶體計算的叢集運算系統, 比 Hadoop MapReduce 快 100 倍.
(2) 支援多程式開發
目前支援 Scala, Python, Java, R
(3) 相容 Hadoop
提供 Hadoop Storage API, 支援 Hadoop HDFS/YARN, 相容 Hive
(4) 跨平台
可在本機或 AWS EC2 雲端執行 - Spark 的核心是彈性分散式資料集 RDD (Risilient Distributed Dataset), 屬於一種分散式記憶體, Spark 會將運算時產生的資料暫存於記憶體中以加快執行速度, 這種方式在資料量大, 反覆運算次數多時越能看出其效能.
- Spark 2.0 主要功能有四 :
(1) Spark SQL DataFrame : 可使用 SQL 語法執行數據分析
(2) Spark Streaming : 可處理即時資料串流
(3) Graphx : 分散式圖形處理架構, 可用圖表運算
(4) Spark MLlib : 可擴充之機器學習函式庫
(5) Spark ML pipeline : 為 ML 每一階段建立 pipeline 流程, 減少程式設計負擔
其中 Spark ML pipeline 是 Spark 從 Python Scikit-learn 模組得到啟發而設計之架構. - Spark 資料處理方式有三種 :
(1) RDD
(2) DataFrame
(3) Spark SQL
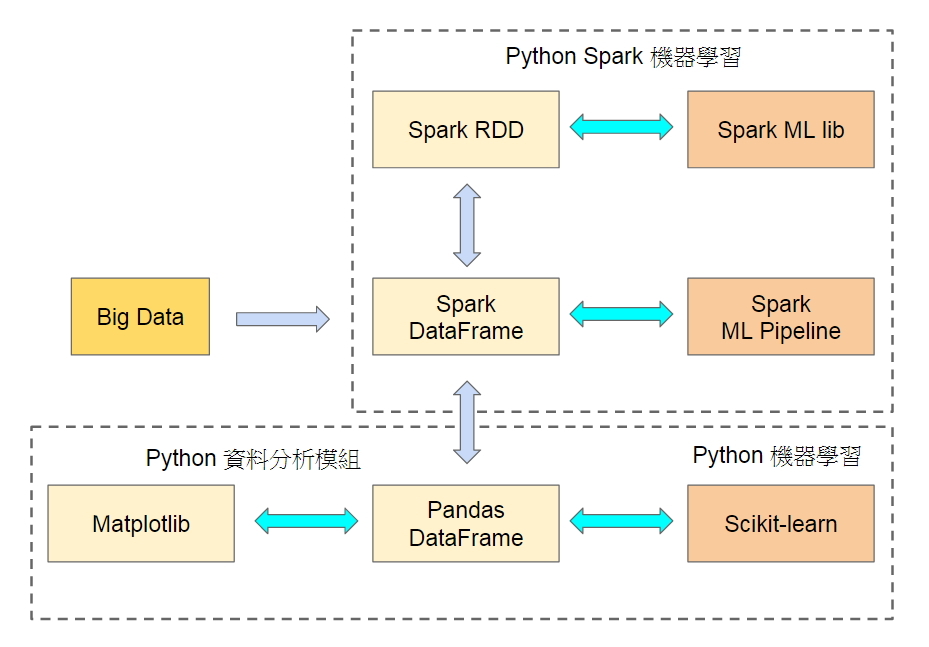
其中 DataFrame 是 Spark 從 Python 的 Pandas 模組得到啟發而設計的.
此三者最大的差異在於是否有定義 Schema (即欄位名稱與資料型態). RDD 資料沒有定義 Schema, 須使用 Map/Reduce 觀念來操作, 對程式設計能力要求較高, 但功能也最強; Spark DataFrame 則須在建立資料前先定義 Schema, 是 Schema 版的 RDD; 而 Spark SQL 則是從 DataFrame 衍生而來, 先建立 DataFrame, 再透過登錄 Spark temp table 使用 SQL 語法操作資料. 使用上以 Spark SQL 最容易, 只需熟 SQL 語法即可; DataFrame 次之, 使用者需要基礎的程式設計能力, 其 API 提供許多與 SQL 功能類似之函數來進行統計; 使用 RDD 則需進階程式設計能力, 因為它沒有 Schema, 必須透過 Map/Reduce 指定資料位置. - Spark 支援以 Scala, Python, Java, R 這四種語言進行應用程式開發, 其中 Scala 是 Spark 本身的開發語言, 與 Spark 相容性最佳, 執行 RDD 操作效率也最高, Scala 與 Java 同樣都是在 JVM 上執行, 也都是物件導向語言, 但 Scala 也兼具函數式語言特性, 程式碼較 Java 簡潔許多, 不過使用者不多, 學習曲線也較陡. Spark 的 R 語言功能支援較不完整, 目前還在持續開發中, 而且 R 不是通用語言, 缺乏網站整合與網路爬蟲功能. 反觀 Python 不僅是通用語言, 其語法簡明易學具備高生產力, 還有 NumPy, Matplotlib, Pandas, Scikit-learn 等資料分析模組支援, 是資料分析與大數據開發之熱門語言.
- Python 雖然擁有 Pandas 與 Scikit-learn 等強大之機器學習模組, 但大數據必須用分散式運算才能有效處理, 這就是 Spark 應運而生的背景, Python 可以透過 Spark 應用程式處理 HDFS 分散式儲存之資料; 亦可在多台電腦組成之群集上執行分散式運算, 利用 Spark 特有之記憶體計算大幅提升執行效能.
- Python Spark 機器學習 API 有兩個 : MLlib 與 ML Pipeline, 前者是搭配 RDD, 後者則是搭配 DataFrame :
(1) Spark MLlib : RDD-based 機器學習 API
(2) Spark ML Pipeline : DataFrame-based 機器學習 API
Spark DataFrame 與 Pandas DataFrame 可以互相轉換, Python 開發者可將資料轉為 Spark DataFrame 後使用 Spark ML Pipeline 進行訓練與預測, 然後轉回 Pandas DataFrame, 這樣就可以利用 Python 豐富的視覺化工具如 Matplotlib 等呈現結果.
Spark DataFrame 提供 API 可輕易讀取其他資料來源, 例如 Hadoop, JSON 等, 也可以透過 JDBC 讀取關聯式資料庫如 MySQL 等. - Spark ML Pipeline 機器學習工作流程 :
Spark ML Pipeline 將機器學習每個階段建立一個 pipeline, 例如資料處理, 訓練, 建立模型, 進行預測, 產生預測結果等等, 優點是模組化可減輕程式設計負擔, 而且全程使用 DataFrame, 資料格式一致, 要套用不同的演算法時直接替換, 流程不變. - 大數據的 3V :
(1) Volumn : 大量資料
(2) Variety : 多樣化資料
(3) Velocity : 資料流速快 - Hadoop 是 Apache 的大量資料儲存與處理平台, 源自於 Doug Cutting 與 Mike Cafarelia 於 2002 年起始的 Nutch 專案, 2004 年導入 Google 的 MapReduce 分散是技術, 於 2006 年改名為 Hadoop 專案. Hadoop 具有如下特性 :
(1) 可擴展性 : 分散式儲存與運算, 只要增加新的資料節點伺服器即可擴充
(2) 經濟性 : 一般等級伺服器即可架構高效能叢集
(3) 彈性 : 可儲存各種形式與來源之資料 (無 Schema)
(4) 可靠性 : 每個資料都有兩個副本 (分散式架構) - HDFS (Hadoop Distributed File System) 分散式檔案系統由 NameNode 與多個 DataNode 組成, NameNode 負責管理維護 HDFS 目錄系統, 控制檔案讀寫動作, DataNode 則負責儲存資料. DataNode 可擴充至成千上萬個. 檔案在儲存時會被切割成多個區塊, 每個區塊會有兩個副本 (總共三份), 也可以在組態設定中指定要建立幾個副本, 當某個區塊毀損時, NameNode 會自動搜尋其他 DataNode 上的副本來回復資料. HDFS 具備機架感知功能, 一份資料的三個副本會分別存放於同機架的不同節點, 以及不同機架的不同節點以避免資料遺失, 即使機架或節點故障仍可保證回復資料.
- MapReduce 中的 Map 是將工作分割成許多小工作交給不同伺服器執行; 而 Reduce 則是指將所有伺服器的執行結果彙整後傳會最終結果. 利用 MapReduce 可在上千台伺服器上平行處理巨量資料. Hadoop 的新版 MapReduce 架構稱為 YARN (Yet Another Resource Negotiator), 是效率更高的運算資源管理核心.
Python Spark 機器學習的架構重繪如下 :
由於 Hadoop 是在 Linux 環境下執行的軟體, 如果要在 Windows 上安裝 Hadoop, 必須使用虛擬機器來安裝 Linux, 此書第二章即介紹如何在 Windows 上安裝設定 Oracle 的免費虛擬機器軟體 VirtualBox. 安裝很簡單, 就是一鍵到底的 YES man 即可. 安裝完成後, 啟動 VirtualBox 進行如下設定 :
- 在 "檔案/喜好設定/一般" 選項下指定 VirtualBox 的檔案資料夾, 例如 D:\VirtualBox.
- 按 "新增" 鈕建立一個虛擬機器, 需輸入名稱 (Hadoop), 選擇類型 (Linux), 版本 (Ubuntu-64), 指定虛擬機器的記憶體大小 (例如 4096MB).
- 下一步選擇 "立即建立虛擬機器硬碟", 按 "建立" 選擇虛擬硬碟檔案格式 VDI.
- 下一步選擇虛擬硬碟配置方式為 "動態配置".
- 下一步設定虛擬硬碟位置與大小, 選擇步驟 2 所指定之虛擬機器名稱 Hadoop, 硬碟大小可設 100G (此為上限而已), 按 "建立" 即可.
完成後在 VirtualBox 檔案資料夾下會產生一個子目錄 Hadoop 用來儲存此虛擬機器之檔案. 安裝好 VirtualBox 之後接下來第三章是在虛擬機器中安裝 Ubuntu 作業系統, 書中建議的是 64 位元的 14.04 LTS 桌面版本 :
# http://www.ubuntu-tw.org/modules/tinyd0
因為下載的是 ISO 光碟檔案, 所以要按 VirtualBox 的 "設定值" 按鈕, 在 "存放裝置" 的 IDE 控制器中按光碟圖示選擇虛擬光碟檔案, 點選所下載之 Ubuntu 的 ISO 檔案, 按開啟與確定後即將光碟掛載上去, 接著按 ViutualBox 的 "啟動" 即可安裝 Ubuntu Linux 了.
Ubuntu 搞定後便可安裝 Hadoop 了, 此書第四章介紹 Hadoop Single Node Cluster 安裝設定方式, 亦即在一台電腦上建立的 Hadoop 執行環境; 第五章則是介紹 Hadoop Multi Node Cluster 安裝方式以及 Hadoop Resource Manager/Name Node HDFS Web 介面, 這要在 VitualBox 上建立多個虛擬主機 (書中是 4 個, 一個 master, 其餘為 data) 來模擬 Hadoop 叢集運算.
關於 Scala 參考 :
# Scala vs Java:兩者間的差異與相似處
沒有留言 :
張貼留言