前兩篇的 SpaCy 測試都是在本機或其官網上執行, 本篇則是要在谷歌 Colab 平台上安裝 SpaCy 與語言統計模型後利用 Google 雲端計算資源來執行自然語言處理管線, 好處是完全不需要擔心本機安裝時可能會遇到的問題, 且可將執行 NLP 任務的過程紀錄下來或分享到 GitHub.
本系列之前的文章參考 :
Colab 是整合於谷歌雲端硬碟上的免費線上運算平台, 用法可參考這篇 :
一. 在雲端硬碟建立資料夾與 Colab :
在谷歌雲端硬碟上安裝 SpaCy 套件與模型之前, 基於資料整理歸檔考量, 最好先建立一個資料夾來收納 ipynb 等相關檔案, 首先按雲端硬碟左上角的 " + 新增" 鈕, 點選 "資料夾" :

在彈出視窗中輸入資料夾名稱, 例如 "SpaCy NLP", 按 "建立" 鈕 :

如此便在雲端硬碟下建立了 "SpaCy NLP" 這個資料夾, 點選進入此資料夾後, 再次按左上角的 "+新增" 鈕, 點選選單中最底下的 "更多", 於次選單中點選 "Google colaboratory" :


{kind=link}
在 Colab 筆記本的程式碼欄位內輸入下列指令安裝 SpaCy :
按欄位前面的 Play 鍵執行安裝, 結果顯示之前已安裝過 2.2.4 版 :

!pip install -U spacy

可見下載安裝了最新的 SpaCy 3.2.3 版.
可再新增儲存格輸入如下指令檢查 SpaCy 版本 :
import spacy
spacy.__version__
結果如下 :

可見確實是 SpaCy 3.2.3 版.
三. 安裝語言的統計模型 :
在 Colab 安裝 SpaCy 的語言模型必須使用 pip 指令線上安裝, 每個語言模型的下載網址可在 SpaCy 官網查詢 :
例如英文與中文的模型網址如下 :
以體積最小的英文模型 en_core_web_sm 為例, 其模型之 whl 檔或 gz 檔查詢方式如下 :


其模型網址為 :
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0-py3-none-any.whl (13.3 MB)
於 Colab 筆記本新增一儲存格, 輸入如下指令安裝此英文模型 :
!pip install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0-py3-none-any.whl
結果如下 :

中文模型 zh_core_web_sm 的 whl 檔網址為 :
https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.2.0/zh_core_web_sm-3.2.0-py3-none-any.whl (47.2 MB)
於 Colab 筆記本新增一儲存格, 輸入如下指令安裝此英文模型 :
!pip install https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.2.0/zh_core_web_sm-3.2.0-py3-none-any.whl
結果如下 :

這樣就可以開始在 Colab 上執行 NLP 管線任務了, 依序新增儲存格輸入如下指令 :
import spacy
nlp=spacy.load('en_core_web_sm')
doc=nlp('I am going to visit the White House.')
print(f'text\tlemma_\ttag_\tpos_\tdep_\thead')
for token in doc:
fstr=(f'{token.text}\t{token.lemma_}\t{token.tag_}\t{token.pos_}\t'
f'{token.dep_}\t{token.head}')
print(fstr)
結果如下 :

注意, 此例中因為 f 字串太長了, 所以將其分兩列放在小括號 () 中.
四. 語法相依關係與命名實體視覺化 :
在 Colab 執行視覺化與在本機使用 Jupyter Notebook 一樣必須呼叫 doc.render() 而不是 doc.serve(), 而且必須傳入參數 jupyter=True 才能在網頁中繪製圖形. 為了簡單起見, 下面改為分析 'I live in Taiwan' 這個句子來分析, 新增儲存格輸入如下指令 :
spacy.displacy.render(doc, jupyter=True)
參考 :
結果如下 :

可見 displaycy.render() 不傳入 style 參數時預設是 'dep', 即繪製語法相依圖. 若傳入 style='ent' 則顯示命名實體標記圖, 例如 :
結果如下 :

上面也安裝了中文模型 zh_core_web_sm, 所以最後來試試中文的視覺化, 輸入如下指令 :
text='''戴笠, 浙江省江山縣人, 中華民國陸軍中將, 生於清光緒 23 年,
國民政府軍統局少將副局長, 蔣介石愛將, 民國 35 年 3 月 17 日於南京上空飛機失事身亡.'''
doc=nlp(text)
spacy.displacy.render(doc, style='ent', jupyter=True)
結果如下 :
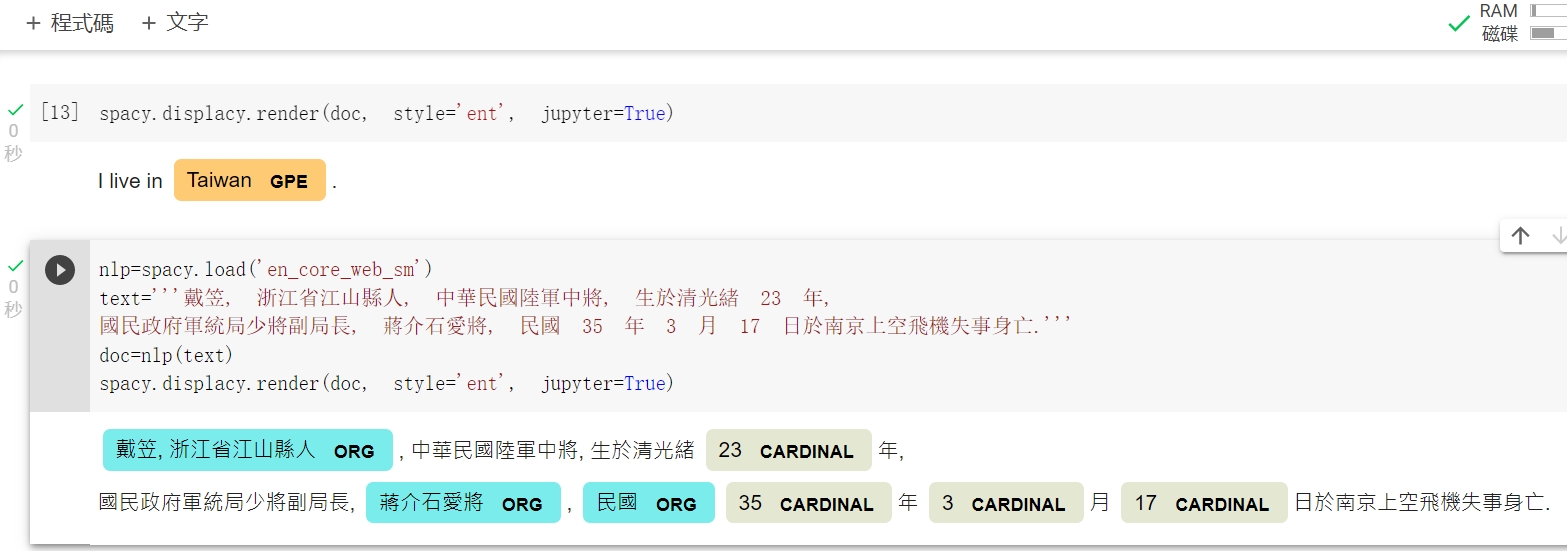
與前一篇測試使用 SpaCy 線上視覺化的輸出有些不一樣, 例如 '蔣介石愛將' 被標記為 ORG (很奇怪), 以及 '南京' 未被辨識出來等, 其餘相同.
在 Colab 上執行 SpaCy 最方便的地方就是會自動記錄執行過程為 ipynb 檔, 以上測試過程我分享於 GitHub, 開啟後可點選 "檔案/在雲端硬碟另存複本" 複製到個人的雲端硬碟上 :
沒有留言:
張貼留言